はじめに
HEROZ ASKのプロトタイプに今年(2024年)に来ると言われているマルチモーダル(Multi modal) RAGを組み込みましたので、その結果について書いていきたいと思います。
HEROZ ASKのプロトタイプは実験やデモ用に新機能や新モデルを使えるようにした試作品です。
なお、本記事はRAGやlangchainのことをある程度理解している人を対象としています。
マルチモーダルRAGの実現方式
マルチモーダルRAGの実現方式はlangchainのblogで解説されています。
この記事によると実現方式には以下の3種類があるとされています。
- Option 1: Retrieve raw image
- Option 2: Retrieve image summary
- Option 3: Retrieve image summary but pass raw image to LLM fir synthesis
 (図はlangchainのblogに掲載されているもの)
(図はlangchainのblogに掲載されているもの)
Option 1はOpenCLIPのようなテキストとイメージをシームレスに取り扱えるマルチモーダルエンベンディング(Multi modal embedding)を使用して、エンべディングと検索を行います。
Option 2とOption 3はイメージを一度GPT-4oやGPT-4Vのようなマルチモーダル対応LLMでサマリーのテキストを取得して、それに対してエンべディングと検索を行います。
Option 2は検索後の回答生成でも検索結果としてサマリーのテキストをそのまま使用しますが、Option 3は検索結果として元のイメージをマルチモーダル対応LLMに送信します。
今回の組み込みではOption 1とOption 3に対応することにしました。
改造ポイント
ドキュメントの保存
ドキュメントの分解にはunstructuredを使用しました。
unstructuredのpartition_pdf()はchunking_strategyの設定によってチャンキングも行えます。その場合には、CompositeElementというelementで内容を取得します。
また、extract_images_in_pdfをTrueにすると、image_output_dir_pathに切り出したイメージが出力されます。extract_element_typesにTableも入れますと、表も切り出されます。
切り出したイメージはbase64にして保存します。アイコンのような小さなイメージも切り出されますので、20kb以下のイメージは無視するようにしています。
Option3ならGPT-4oやGPT-4Vでサマリーを取得します。
Option1の場合には、embeddingに含まれるembed_image()を使用してベクトル化します。今回はOption1用のembeddingとしてOpenClipのマルチリンガルモデルであるCLIP-ViT-H-14-frozen-xlm-roberta-large-laion5B-s13B-b90kを使用しました。
コードを見る
!apt-get install libgl1-mesa-dev poppler-utils tesseract-ocr tesseract-ocr-jpn !pip install cmake !pip install unstructured[pdf]==0.11.8 langchain openai langchain-openai from unstructured.partition.pdf import partition_pdf from langchain.docstore.document import Document from langchain_openai import ChatOpenAI from langchain.schema.messages import HumanMessage import tempfile import base64 import os from io import BytesIO os.environ["OPENAI_API_KEY"] = "(OpenAIのキー)" filename = "(ファイル名)" option_mode = "option3" def encode_image(image_path): with open(image_path, "rb") as image_file: return base64.b64encode(image_file.read()).decode('utf-8') def summarize_image(image_base64): prompt = """あなたは画像の内容を説明する役割をもっています。 入力された画像の内容を詳細に説明してください。 基本的には日本語で回答してほしいですが、専門用語や固有名詞を用いて説明をする際には英語のままで構いません。 """ chat = ChatOpenAI(model="gpt-4-vision-preview", max_tokens=1024) human_message = [ HumanMessage(content=[ {"type": "text", "text": prompt}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{image_base64}"}} ]) ] msg = chat.invoke(human_message) return msg.content docs = [] with tempfile.TemporaryDirectory() as image_dir: elements = partition_pdf( filename, strategy="hi_res", languages=['jpn', 'eng'], extract_images_in_pdf=True, extract_element_types=["Image", "Table"], infer_table_structure=True, chunking_strategy="by_title", max_characters=800, # チャンクサイズ new_after_n_chars=760, image_output_dir_path=image_dir, ) for element in elements: if "unstructured.documents.elements.CompositeElement" in str(type(element)): element_text = str(element) # テキストをいろいろ加工 metadata = {"source": filename, "type": "text"} docs.append(Document(page_content=element_text, metadata=metadata)) for image_file in sorted(os.listdir(image_dir)): if image_file.endswith('.jpg'): image_path = os.path.join(image_dir, image_file) if os.path.getsize(image_path) <= 20 * 1024: # 20kb以下のファイルは無視 continue image_base64 = encode_image(image_path) if option_mode == "option1": metadata = { "source": filename, "type": "image", } docs.append(Document(page_content=image_base64, metadata=metadata)) elif option_mode == "option3": image_text = summarize_image(image_base64) metadata = { "source": filename, "type": "summary_image", "original": image_base64, } docs.append(Document(page_content=image_text, metadata=metadata)) vectorstore = (何かしらのベクトルストア) for doc in docs: if not "type" in doc.metadata \ or doc.metadata["type"] in ["text", "summary_image"]: vectorstore.add_documents([doc]) elif doc.metadata["type"] == "image": embeddings = vectorstore.embedding_function.embed_image( [BytesIO(base64.b64decode(doc.page_content))] ) vectorstore.add_embeddings( texts=[doc.page_content], embeddings=embeddings, metadatas=[doc.metadata], )
retrieve結果の集約
langchainのConversationalRetrievalChainチェインを使用してRAGを行っている場合には、retrieverで取得した情報をCombineDocumentsChainチェインで一つのinputsにまとめてからLLMへの問い合わせを行っています。
この部分もマルチモーダル対応をする必要があるため、CombineDocumentsChainチェインの一つであるStuffDocumentsChainチェインに含まれる_get_inputs()を改造しました。
冒頭のテキスト部分はそのままで、途中にイメージ関係の処理を追加しています。
retrieverで取得したイメージについては配列にして、キー"image"でinputsに追加するようにしました。また、input_variablesにもキー"image"を追加しています。
コードを見る
class CustomStuffDocumentsChain(StuffDocumentsChain): def _get_inputs(self, docs: List[Document], **kwargs: Any) -> dict: """Construct inputs from kwargs and docs.""" # Format each document according to the prompt doc_strings = [format_document(doc, self.document_prompt) for doc in docs if not "type" in doc.metadata or doc.metadata["type"] == "text"] # Join the documents together to put them in the prompt. inputs = { k: v for k, v in kwargs.items() if k in self.llm_chain.prompt.input_variables } inputs[self.document_variable_name] = self.document_separator.join(doc_strings) # images image_docs = list(filter(lambda doc: "type" in doc.metadata and doc.metadata["type"] in ["summary_image", "image"], docs)) if (hasattr(self.llm_chain.llm, "model_name") \ and self.llm_chain.llm.model_name in ["gpt-4-vision-preview", "gpt-4o"] \ and len(image_docs) > 0: images = [] for doc in image_docs: if doc.metadata["type"] == "summary_image": metadata = { "file_id": doc.metadata["file_id"], "source": doc.metadata["source"], "type": doc.metadata["type"], "summary": doc.page_content, } images.append(Document(page_content=doc.metadata["original"], metadata=metadata)) elif doc.metadata["type"] == "image": images.append(doc) inputs["images"] = images if not "images" in self.llm_chain.prompt.input_variables: self.llm_chain.prompt.input_variables.append("images") return inputs
マルチモーダル形式への変更
langchainのプロンプトテンプレートはGPT-4oやGPT-4VといったマルチモーダルLLMの入力には対応していないようでしたので、その部分も改造するようにしました。以下はHumanMessagePromptTemplateに含まれるformat()を改造した時の例です。
テキストのみの場合には従来の処理をして終了します。
マルチモーダルの場合には配列にテキストとイメージを順番にdict形式で追加していきます。
コードを見る
class CustomHumanMessagePromptTemplate(HumanMessagePromptTemplate): """Human message prompt template. This is a message sent from the user.""" model_name: str def format(self, **kwargs: Any) -> BaseMessage: """Format the prompt template.""" text = self.prompt.format(**kwargs) if not self.model_name in [ "gpt-4-vision-preview", "gpt-4o", ]: return HumanMessage(content=text, additional_kwargs=self.additional_kwargs) content = [] content.append({"type": "text", "text": text}) if "images" in kwargs: for image in kwargs["images"]: content.append({ "type": "image_url" , "image_url": {"url": "data:image/jpeg;base64," + image.page_content } }) return HumanMessage(content=content, additional_kwargs=self.additional_kwargs)
組み込み結果
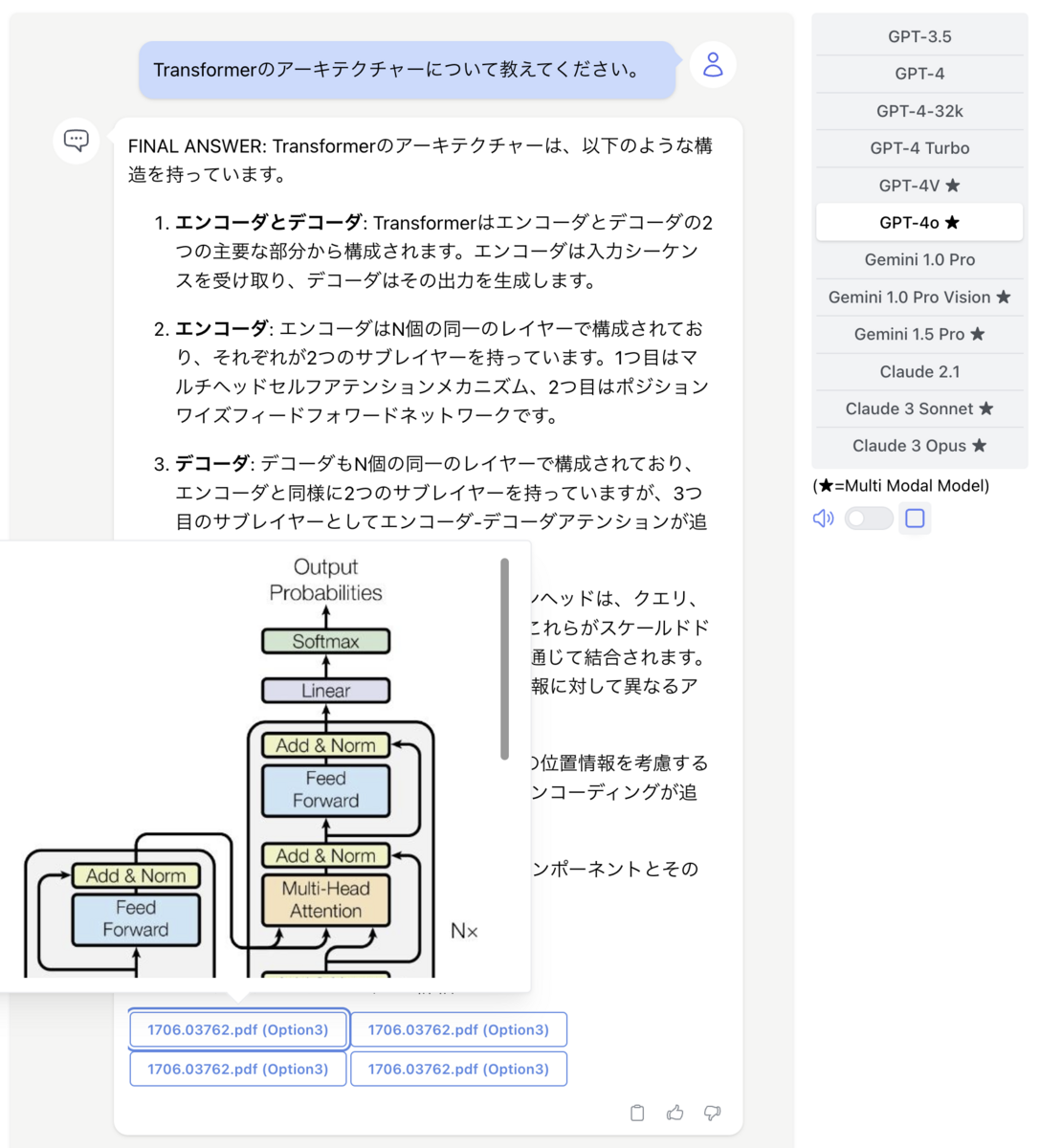
上記の改造をlangchain側に施し、UIを調整すると以下のように無事にマルチモーダルのRAGを実現することができました。
この例では資料として有名なTransformerの論文を読み込ませた上で、質問しています。
論文内のTransformerのアーキテクチャー図を元にした解説が返ってきました。
意外とイメージ中の文字を正しくスキャンできていたり、表の構造を正しく理解していて驚きました。
特にGPT-4oになってからは文字の認識精度は格段に上がっています。
そして、HEROZ ASKの機能である参照文の表示でもイメージを表示できるようにしています。
マルチモーダルRAGは成功しましたが、以下のような課題(苦労話)もありました。
トークン数の計算
langchainのConversationalRetrievalChainチェインではretrieverで取得した情報のトークン数が最大トークン数より多い場合には、スコアが低いチャンクを切り捨てる_reduce_tokens_below_limit()という関数があります。
イメージをマルチモーダル対応LLMに送る場合にはトークン数の計算が異なるため、この関数も改造する必要がありました。
特にOption1の場合には本文(page_content)にbase64でエンコードしたイメージを格納しているため、そのままだとすぐに最大トークン数を超過してしまい、1枚もイメージが送られなかったことがありました。
Option1の精度
Option1でマルチモーダルRAGを試したところ、テキストとイメージが混在しているドキュメントではイメージの部分がヒットしないという現象がありました。
調査してみますと、テキストとイメージでretrieveのスコアが4倍ぐらい異なっていることが分かりました(イメージのスコアがテキストのスコアの1/4)。
OpenClipのようなマルチモーダルエンベンディング(Multi modal embedding)はテキストとイメージがシームレスに取り扱えるかと思っていましたが、現実的には同じスケールで評価されないようです。
Option3はイメージを一度サマリーにして検索するので情報の抜け落ちが気になりますが、テキストとイメージが混在している場合はOption3でしかうまく動作しませんでした。
テキストとイメージがよりシームレスに評価されるマルチモーダルエンベンディングが登場することが待ち望まれます。
図表のタイトル付与
マルチモーダルRAGも動作するHEROZ ASKのプロトタイプは第8回 AI・人工知能EXPO【春】で展示しており、パワーポイントで作成されたグラフや表入りの決算資料を検索するデモを準備していました。
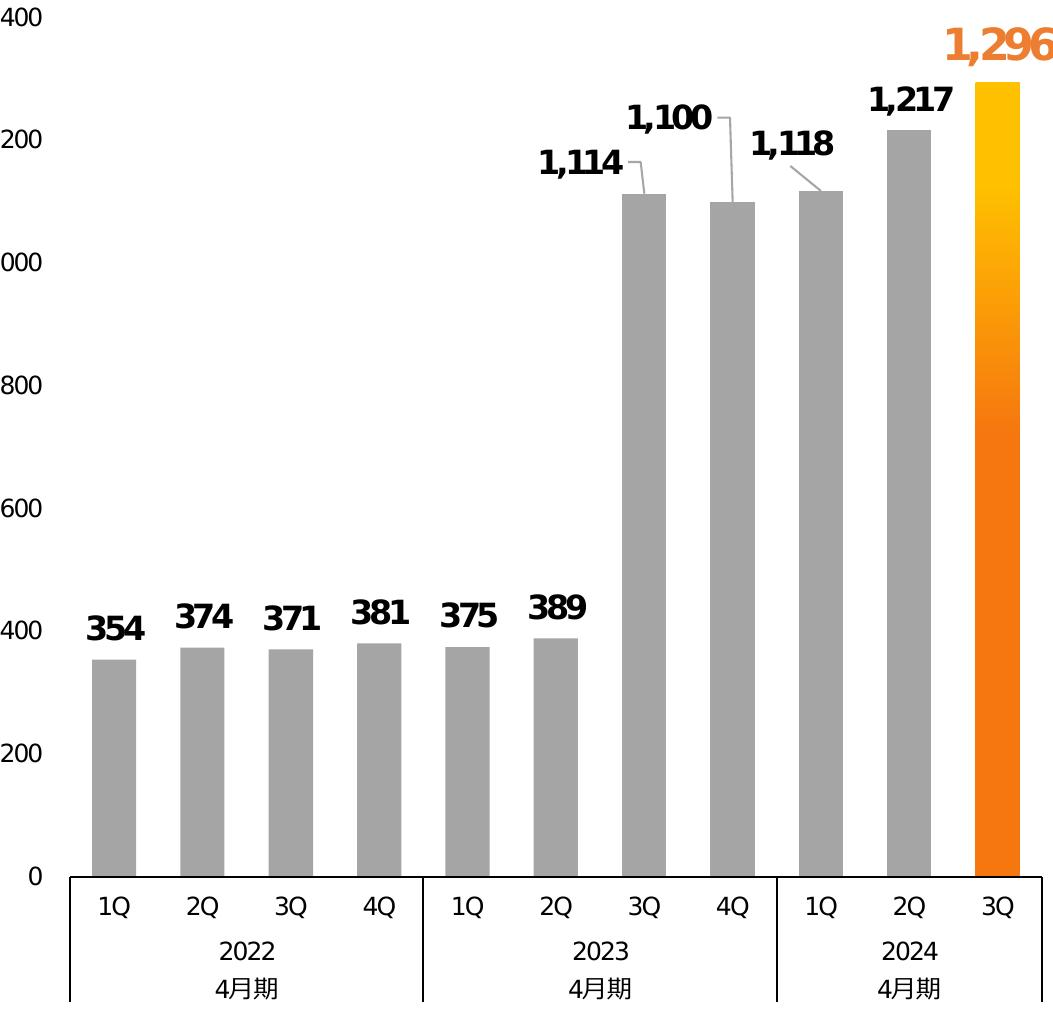
ところが、unstructuredで切り出したグラフや表は、以下のようにグラフや表の単体になってしまい、前後の文脈である何に対するものかが分からないものになっていました。
このため、マルチモーダルRAGでうまく検索できない問題が発生しました。
例のグラフは弊社決算資料のものです。
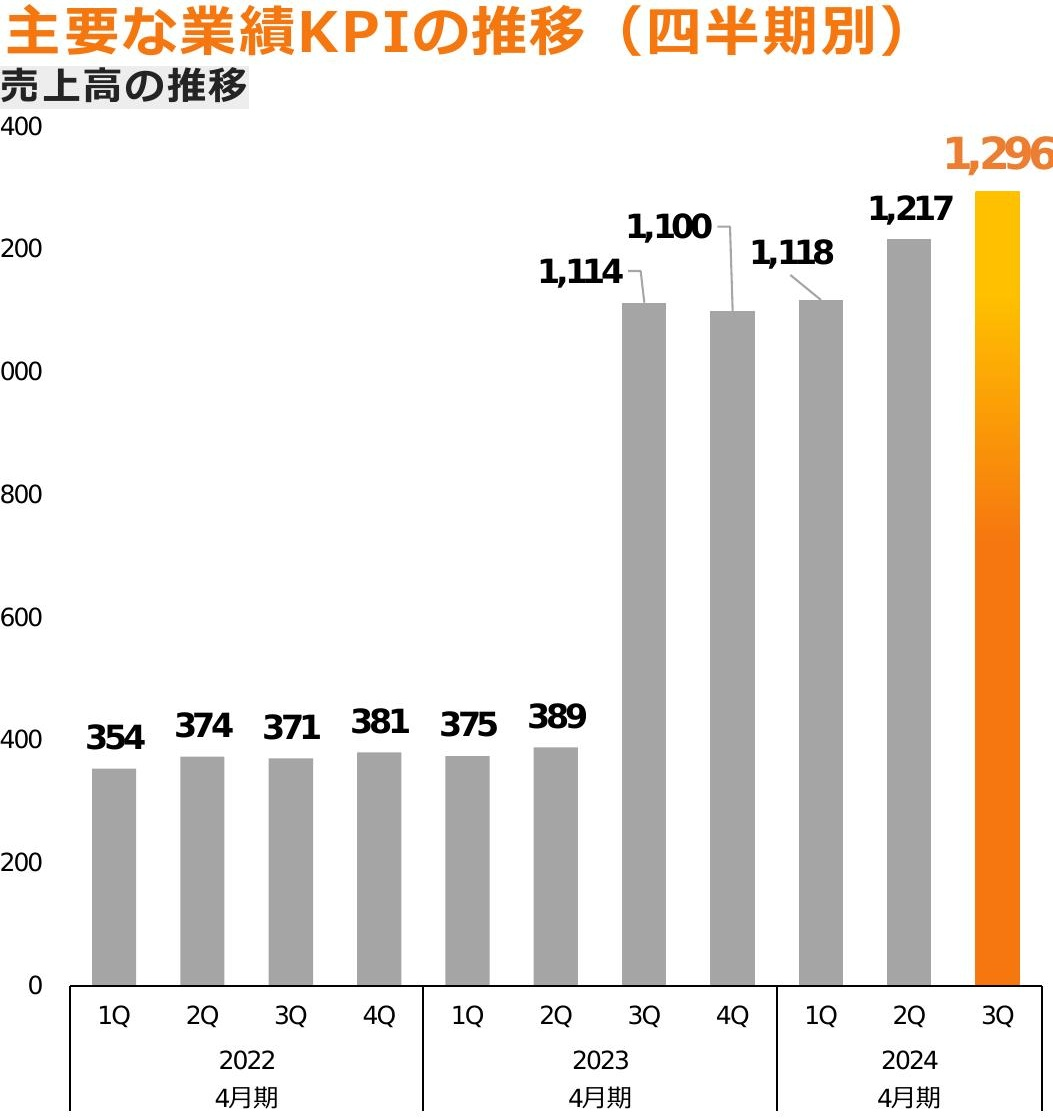
こちらについては、ヘッダーやタイトルも同時に切り出して、元のイメージに無理やりそれらを合成することで解消しました。
以下の改良後のグラフには「売上高」という文字列が含まれるようになったため、「2024年3Qの売上高は?」のような質問も正しく回答するようになりました。(正解はグラフ中の1,296百万円)
今回は展示会のデモ用に限定的な条件で動作するようにしましたが、より汎用的に使えるようにすることは大きな課題だと思います。
おわりに
今回はマルチモーダルRAGをHEROZ ASKのプロトタイプに組み込み、無事に図表を含めて検索できることに成功しました。
そして、これを第8回 AI・人工知能EXPO【春】の弊社ブースで展示し、多くのお客様から驚きの反応を頂くことができました。
一方で、上記にも書いたように、
- マルチモーダル対応LLMの認識精度
- 前後の文脈を補完する方法
あたりはまだまだ課題であることが分かりました。
今後は、この辺りの課題をLLMの発展や技術改良により解決して、製品化できるようにしたいと思います。