はじめに
昨今、小規模言語モデル(SLM, Small Language Model)の話が生成AI界隈で賑わせています。
SLMはgpt-4oのような大規模言語モデル(LLM, Large Language Model)と比較して小型軽量である故に以下のような特徴があるとされています。
- エッジデバイスやオンプレサーバーで動作させることができる。動作させてもコストが大きくならない。
- セキュリティーやプライバシーの問題で海外のサーバーへプロンプトを送ることに対しての抵抗は根強くあると思います。
- 応答までのレイテンシーが短い
- 特に音声会話のような場合にはミリ秒(ms)を争うので、レイテンシーが低いに越したことはないです。
- ドメイン特化のためのファインチューニングを実施しやすい。
- 従来の中規模や大規模のモデルと比べてはるかに少ないGPU枚数でファインチューニングができるので、敷居が下がることを期待できます。
弊社でもSLMの動向は追っていましたが、以前の実験のように小規模のモデル(この時は10B前後)だと大した精度が出ないと考えていましたので、スルーしていました。
ところが、最近のSLMは以前のgpt-3.5-turboに匹敵する精度が出るという話や、精度が多少劣っても使い所があるかもしれないという話を聞き、遅ればせながら社内向けの環境に導入して、いろいろ検証しようと思いました。
検証に使用したSLMは今年の8月にリリースされたMicrosoft社のPhi-3.5の中で最も軽量なPhi-3.5 mini instructとしました。Phi-3.5 mini instructは3.8Bとかなり軽量です。
これをAzure Machine Learning サーバーレスAPIで動作させました。Phi-3.5 mini instructは1000トークンあたり$0.00013で推論できます。
HEROZ ASKに組み込むにあたってはlangchainで動作するようにしなければならないのですが、Azure Machine Learning サーバーレスAPIへの接続に関する情報がほとんどありませんでしたので、こちらに書こうと思います。
モデルのデプロイ
langchainからの呼び出しにはAzureMLChatOnlineEndpointを使用するのですが、こちらはAzure Machine Learning Studioでデプロイしたモデルにしか対応していませんでした。
先日のIgnite 2024でデビューしたAzure AI Foundryでデプロイしたモデルにはつながらず、少しハマりました。
以下がMachine Learning Studioでのモデルのデプロイ方法です。
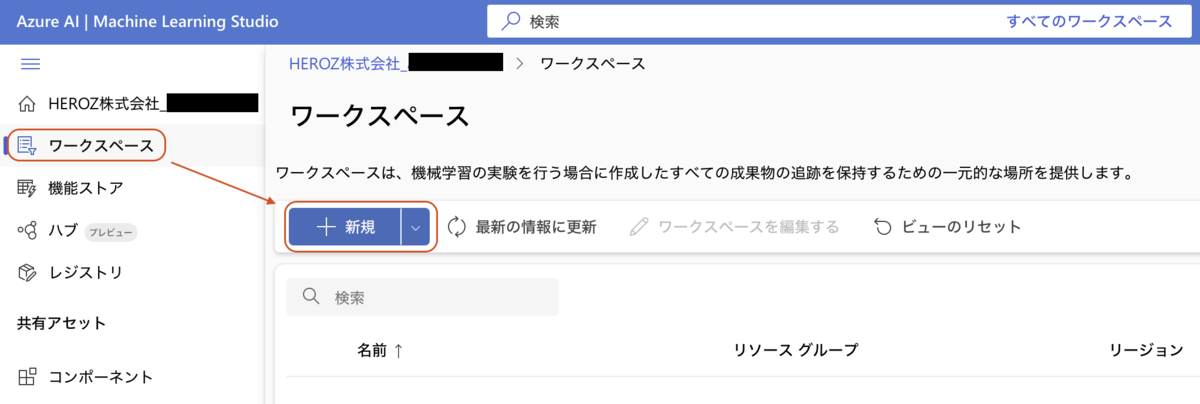
1. ワークスペースの作成
Azure Machine Learning Studioにログインし、ワークスペースを作成する。
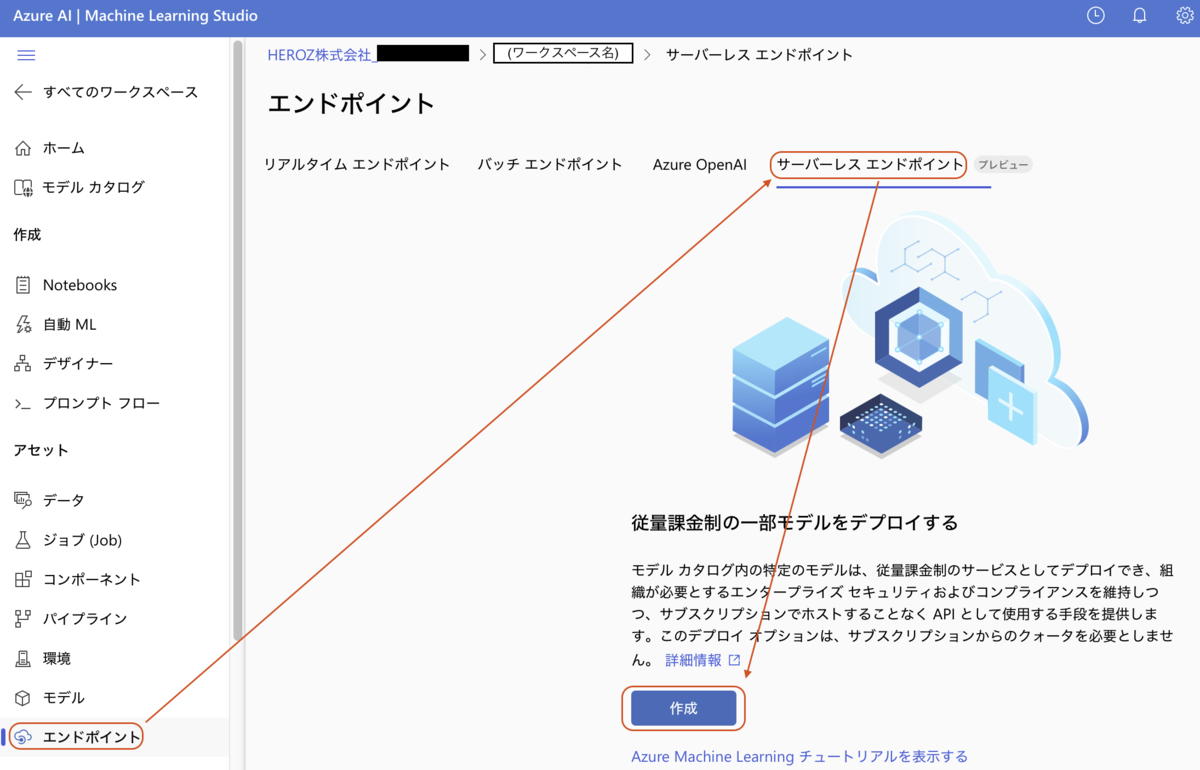
2. サーバーレスエンドポイントの作成
作成したワークスペースに入り、エンドポイントページのサーバーレスエンドポイントタブからサーバーレスエンドポイントを作成する。
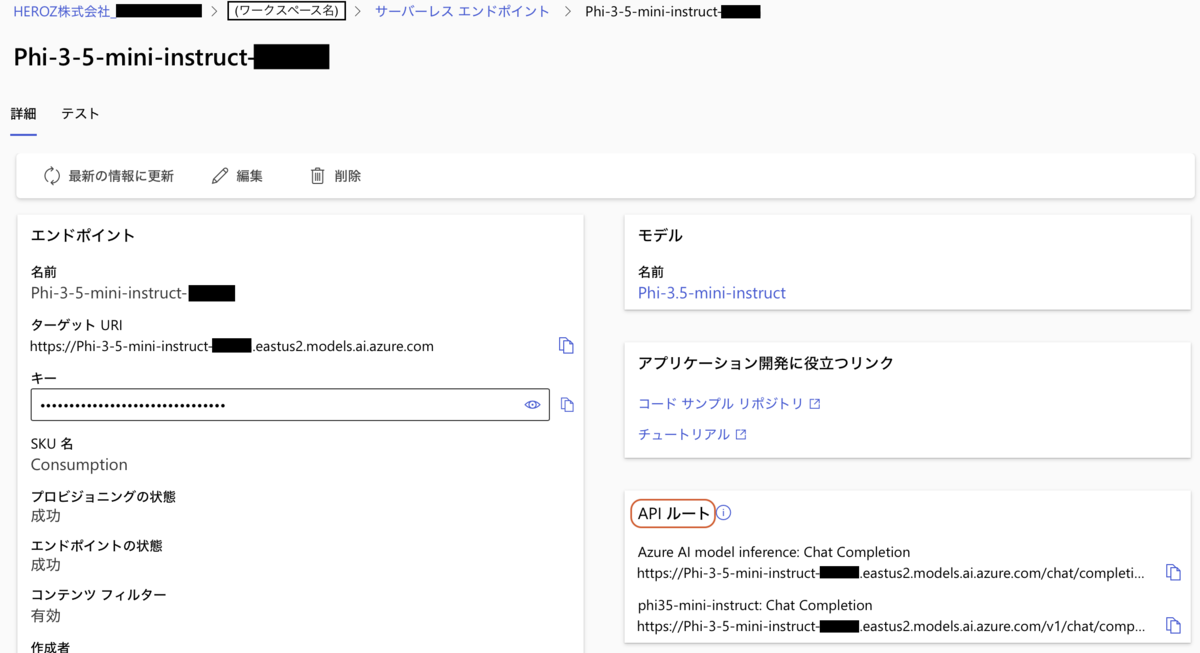
3. エンドポイントの詳細
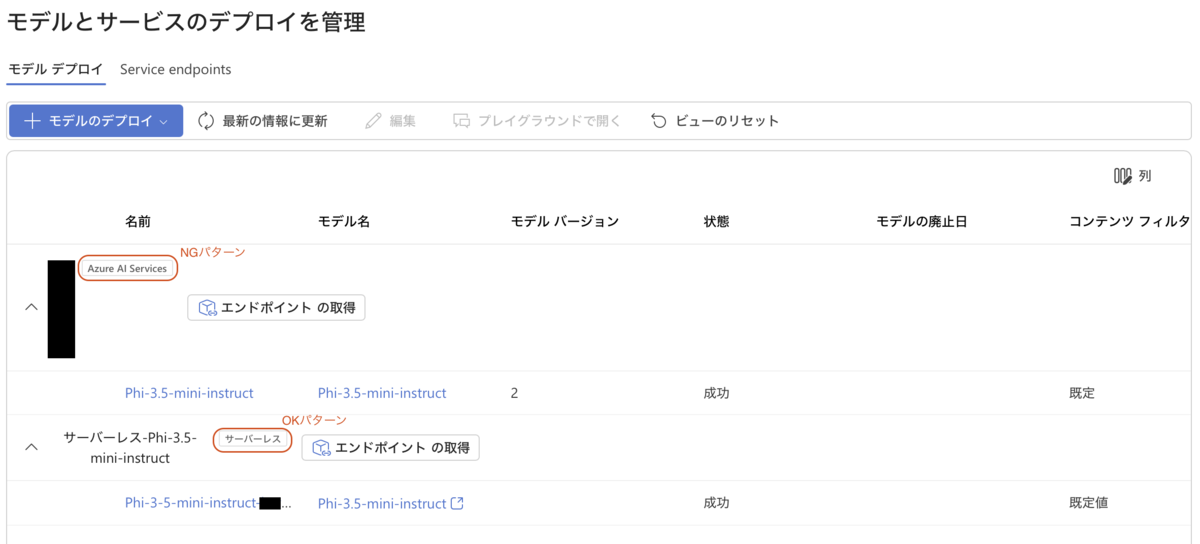
作成したエンドポイントの詳細ページを開くと、エンドポイントのURLとAPIキーを取得できます。この時に「APIルート」のパネルがあることがポイントです。
Azure AI Foundryで作成したエンドポイントとの比較
Azure AI Foundryで作成したエンドポイントの詳細には「APIルート」が存在しません。
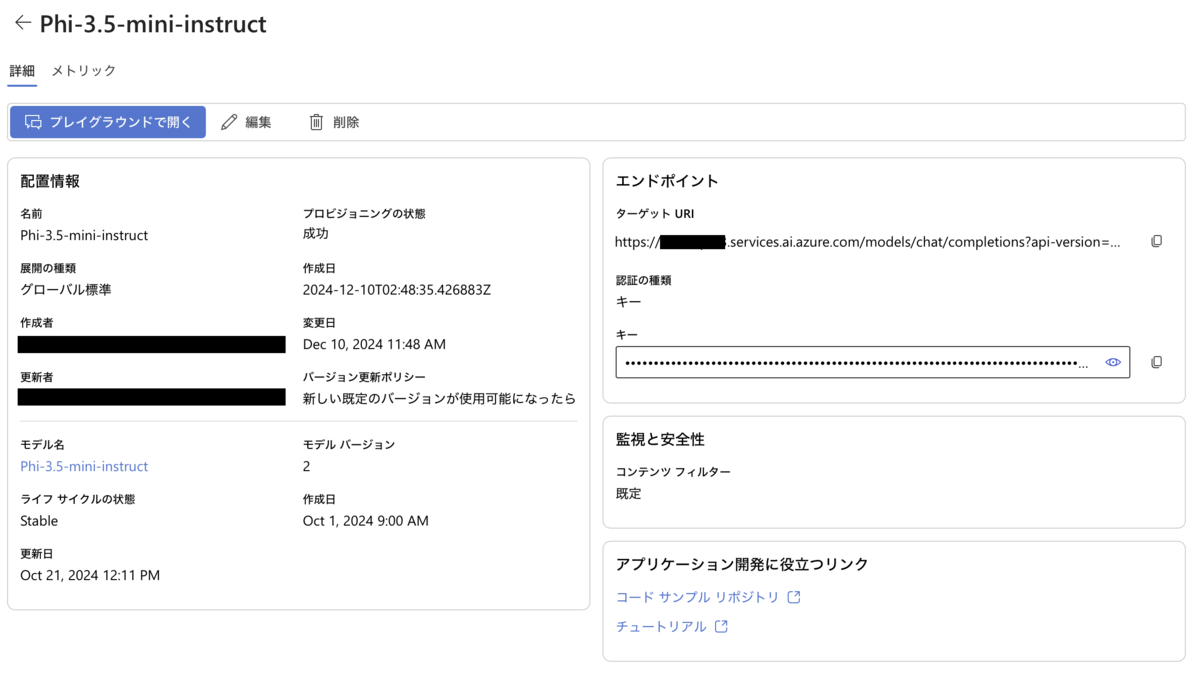
Azure AI Foundryのエンドポイント一覧では、Machine Learning Studioで作成したOKの方のエンドポイントは「サーバーレス」となっていて、AI Foundryで作成したNGの方のエンドポイントは「Azure AI Services」となっています。
langchainからの呼び出しコード
langchainからは以下のコードにて呼び出すことができます。
!pip install langchain langchain_community from langchain_core.prompts import ChatPromptTemplate from langchain_community.chat_models.azureml_endpoint import AzureMLChatOnlineEndpoint, AzureMLEndpointApiType, CustomOpenAIChatContentFormatter AZURE_PHI3_ENDPOINT="(エンドポイント)" AZURE_PHI3_API_KEY="(APIキー)" human = "あなたは何者ですか?" prompt = ChatPromptTemplate.from_messages([("human", human)]) chat = AzureMLChatOnlineEndpoint( endpoint_url=AZURE_PHI3_ENDPOINT, endpoint_api_type=AzureMLEndpointApiType.serverless, endpoint_api_key=AZURE_PHI3_API_KEY, content_formatter=CustomOpenAIChatContentFormatter(), ) chain = prompt | chat chain.invoke({}) → AIMessage(content='私はMicrosoftのAIアシスタントです。...
Azure AI Foundryで作成したエンドポイントもlangchain_azure_aiに含まれるAzureAIChatCompletionsModelを使えば呼び出せるような記事はありました。ただし、現時点(2024/12/12)ではlangchain_azure_aiはままだ非公開のようです。
実行結果
HEROZ ASKの社内環境に組み込み、無事に動作しました。
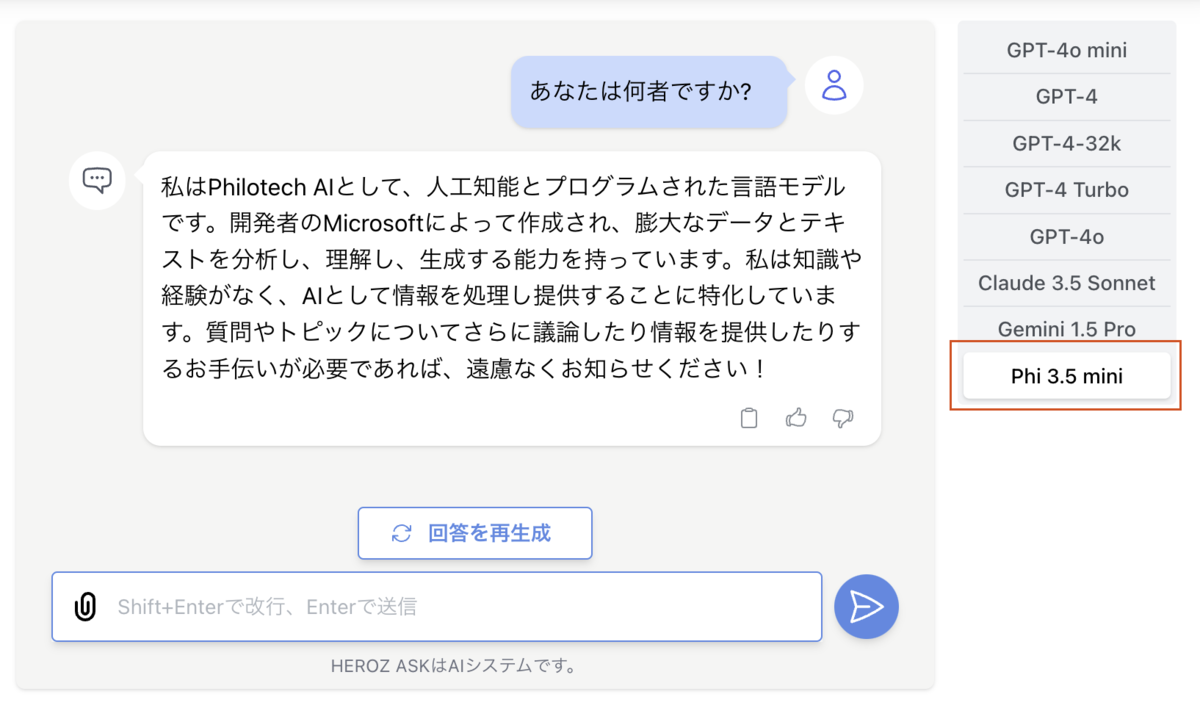
以下、実行して気になったことです。
モデルの精度と推論速度
モデルの精度については、プロンプトの些細な違いによっては壊れた回答になったり、Few-shotの例に引きづられすぎたりといった小中規模のオープンソースのモデルにありがちな間違いが発生することもありますが、プロンプトが合っていれば正しい回答を得られることは確認できました。
また、Azure Machine Learning サーバーレスAPIによる推論速度はモデルサイズの割には速くはなかったです。
やはりサーバーレスタイプですと、起動のオーバーヘッドがそれなりにあるのかもしれません。
ストリーミング
AzureMLChatOnlineEndpointは_(a)generate()関数から呼ばれる時にはストリーミングにならないことが分かりました。
そこで、以下のようなラッピング関数を作成して、_(a)stream()関数に分岐するようにしました。
コードを見る
from typing import Any, List, Optional from langchain_core.callbacks import ( AsyncCallbackManagerForLLMRun, CallbackManagerForLLMRun, ) from langchain_core.language_models.chat_models import ( agenerate_from_stream, generate_from_stream, ) from langchain_core.messages import BaseMessage from langchain_core.outputs import ChatResult class AzureMLChatOnlineEndpointStreaming(AzureMLChatOnlineEndpoint): streaming: bool = False def _generate( self, messages: List[BaseMessage], stop: Optional[List[str]] = None, run_manager: Optional[CallbackManagerForLLMRun] = None, stream: Optional[bool] = None, **kwargs: Any, ) -> ChatResult: should_stream = stream if stream is not None else self.streaming if should_stream: stream_iter = self._stream( messages, stop=stop, run_manager=run_manager, **kwargs ) return generate_from_stream(stream_iter) return super()._generate(messages, stop, run_manager, *kwargs) async def _agenerate( self, messages: List[BaseMessage], stop: Optional[List[str]] = None, run_manager: Optional[AsyncCallbackManagerForLLMRun] = None, **kwargs: Any, ) -> ChatResult: should_stream = self.streaming if should_stream: stream_iter = self._astream( messages, stop=stop, run_manager=run_manager, **kwargs ) return await agenerate_from_stream(stream_iter) return await super()._agenerate(messages, stop, run_manager, *kwargs)
使用トークン数の取得
AzureMLChatOnlineEndpointならびにAzure Machine Learning サーバーレスAPI上のPhi-3.5モデルは"stream_usage"に対応していないようですので、使用トークン数が取得できませんでした。
今回は社内向けなので使用トークン数は気にしなくてもよいですが、本番サービス向けには使用トークン数を取得する方法を検討する必要がありそうです。
(デバッグしている限りではストリーミングの途中では使用トークン数を配信しているようですが、AzureMLChatOnlineEndpointが拾っていないようです。また、回答完了時に使用トークン数を返すこともなかったです)
おわりに
今回は話題のSLMについて、Phi-3.5をHEROZ ASKの社内環境で動作させることに成功しました。
まだ多くは触っていないですが、社内で精度限界の検証ならびにユースケースの発掘を引き続き進めていきたいと思います。
何か分かりましたら、別途記事にしようと思います。